Utiliser l'IA pour améliorer la recherche documentaire



Depuis l'avènement de ChatGPT, la vision d'un chatbot capable de répondre à toute question liée aux connaissances internes fait rêver les entreprises du monde entier. Cependant, cette aspiration bute sur les limites inhérentes aux assistants basés sur le chat : ils ne peuvent traiter qu'une poignée de passages de documents à la fois, hallucinent facilement des détails, et posent des contraintes de confidentialité des données.
En y regardant de plus près, ce dont les entreprises ont vraiment besoin est d'une nouvelle sorte de solution de recherche : une solution qui non seulement récupère la bonne information, mais qui peut aussi accomplir des tâches de traitement de l'information récupérée – comme le ferait un stagiaire.
Nous travaillons sur cette vision, en tirant parti de nombreuses avancées récentes en IA Générative. Voici comment.
Combler l'écart avec la recherche sur le web
Les outils de recherche en entreprise ont historiquement été moins efficaces que la recherche sur le web, et échouent souvent à retrouver des informations de grande valeur, même au sein des meilleurs outils de productivité (Dropbox, Google Drive, OneDrive, etc.).
Cependant, les avancées en IA — et plus récemment en IA Générative — peuvent aider à combler cet écart.
Les sites web se démènent pour être découvrables, les documents s'en fichent.
Sur le web, chaque site utilise des stratégies de SEO pour s'assurer qu'il est trouvable et considéré comme faisant autorité par les moteurs de recherche. Toutes les pages web utilisent le même format structuré — HTML — rendant les composants de la page stables (titre, niveau des titres, métadonnées, …). Les pages web sont également interconnectées par des hyperliens, permettant l'identification des sites faisant autorité avec l'idée centrale suivante : « Un site web est important si d'autres sites importants lui sont liés ». Cette approche récursive pour déterminer l'importance d'un site, connue sous le nom de PageRank1, bénéficie de la nature interconnectée du web.
Les fichiers, à l'inverse, sont isolés (non reliés), désorganisés, et pour la grande majorité n'ont pas de format structuré. Ils ne se soucient pas d'être trouvés. Personne ne fait leur « SEO » pour améliorer leur découvrabilité.
Utiliser l'IA pour faire le « SEO des documents » et les rendre découvrables
Les avancées en IA peuvent aider à améliorer la découvrabilité de vos documents, comme si des employés à plein temps faisaient leur « SEO ». Cela peut être présenté comme un processus en deux étapes :
- Compréhension des documents : L'IA permet de lire n'importe quel type de contenu et d'extraire des informations depuis le contenu du fichier.
- Lier les documents entre eux : L'IA peut être utilisée pour détecter des références implicites, soit sous forme d'entités mentionnées dans les deux documents — comme des organisations, des personnes, des lieux — soit sous forme de proximité sémantique résultant de la comparaison de chaque document avec tous les autres (On2)4.
Ce sont deux axes de recherche que nous explorons chez Entropia pour améliorer la découvrabilité des documents d'entreprise.
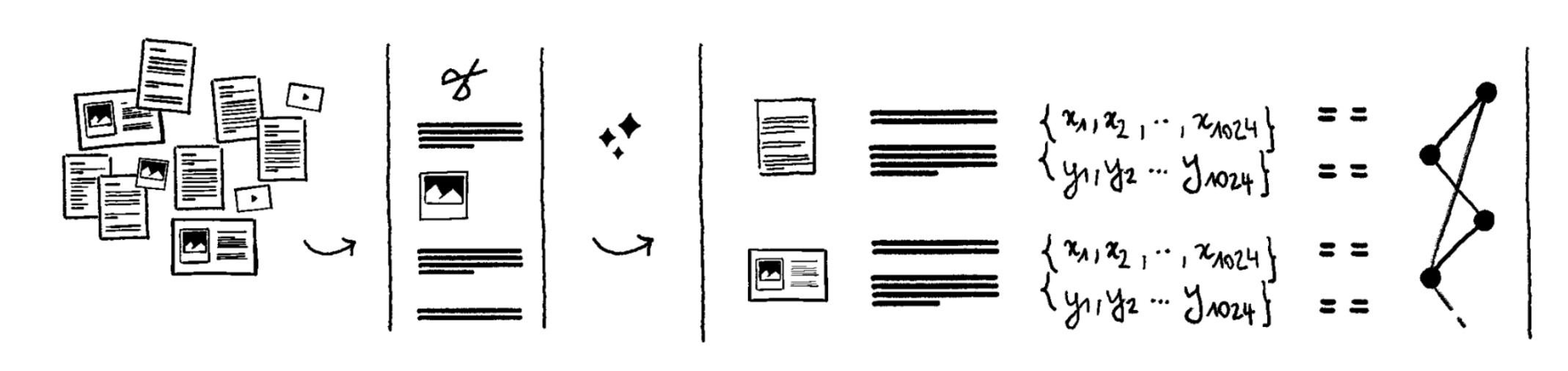
Utiliser l'IA pour comprendre les requêtes et retrouver les informations pertinentes
Les outils de productivité ne supportent que la recherche par mots-clés dans les titres des documents, et parfois dans le contenu des fichiers, avec de grandes limitations pour les PDFs, les scans et les images.
L'expérience montre que les mots-clés ne suffisent pas pour rechercher efficacement parmi des millions de documents. Les gens ne se souviennent souvent pas des mots-clés exacts ou ont besoin de trouver des informations connexes (et pas seulement des correspondances exactes). C'est pourquoi nous avons expérimenté des méthodes de récupération avancées basées sur l'IA (voir ci-dessous) offrant aux utilisateurs plus de flexibilité pour exprimer ce qu'ils recherchent en langage naturel.
Avec ces techniques, nous pouvons retrouver des documents bien plus pertinents en lien avec la requête de l'utilisateur. Nous devons ensuite décider comment les ordonner.
Utiliser l'IA pour simuler des requêtes afin d'optimiser les algorithmes de classement
Les moteurs de recherche publics bénéficient de milliards de requêtes pour optimiser leur classement des documents. Chaque clic sur un résultat de recherche Google est un signal que ce site était le plus pertinent pour la requête, ajoutant ce couple (requête, site) à une base de données utilisée plus tard pour améliorer les algorithmes de classement (ranking).
Les fournisseurs de solutions d'Enterprise Search n'ont pas de tels bases de données, car elles n'ont pas l'échelle d'un moteur de recherche public, et parce qu'elles ne peuvent pas vraiment en collecter sans compromettre leurs engagements de confidentialité.
Nous avons l'intention de combler cet écart avec des jeux de données synthétiques générés par une gamme de LLMs configurés avec différents profils d'utilisateurs. Lors de l'indexation des documents d'une entreprise, nous pouvons simuler des millions de couples (requête, document) pertinents, comme si des milliers d'employés recherchaient des documents toute la journée.
Comme cela a été démontré récemment, les jeux de données synthétiques5 sont plus efficaces que les jeux de données bruyants du monde réel pour entraîner des SLMs. Ils seraient donc des candidats parfaits pour entraîner nos modèles d'IA personnalisés pour chaque client, tout en préservant un niveau de confidentialité maximal.
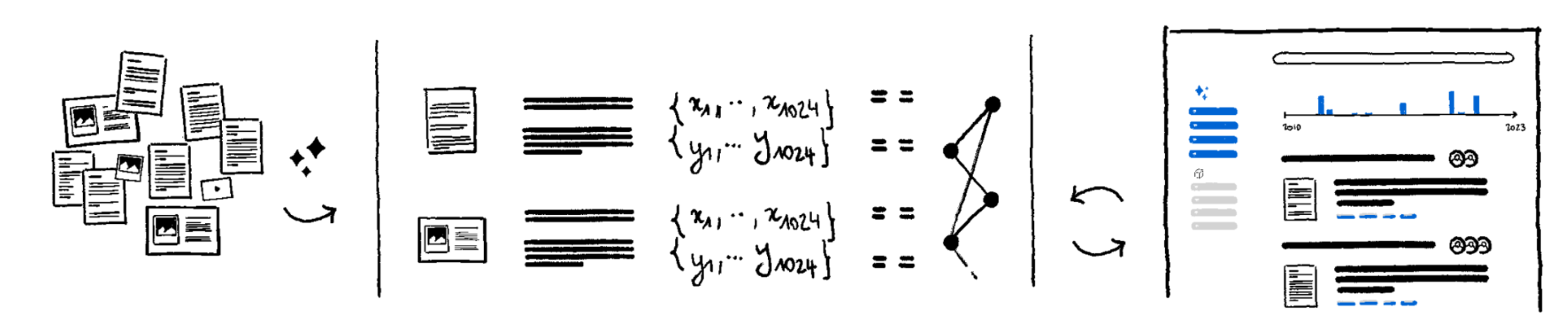
Gérer les tâches de d'analyse et de traitement des documents
Au-delà de la recherche : des automatisations de process
Une fois que vous pouvez récupérer facilement des informations pertinentes au sein de vos fichiers, vous pouvez les utiliser comme inputs pour différentes applications aval, et automatiser des actions.
Nous croyons que chaque employé délèguera bientôt quotidiennement des tâches de traitement d'information à des modèles d'IA, tout comme ils le feraient à un stagiaire. Ce sera un peu comme utiliser Excel aujourd'hui, car utiliser Excel consiste à déléguer des calculs complexes à une machine. Et cela réduira certainement le besoin de logiciels ad-hoc.
C'est notre objectif à moyen terme : permettre progressivement de telles applications et offrir aux équipes du monde entier un vivier presque infini de "stagiaires" prêts à exécuter des tâches pour elles.
- Appel d'offres : Une société de conseil doit répondre à un appel d'offres et demande à Documentalist de :
- lire chaque question de l'appel d'offres,
- rechercher tous les documents contenant des informations pour y répondre (ou lui fournir un ensemble de documents identifiés avec lesquels travailler)
- lire ces documents et prendre des notes dans un brouillon6
- passer d'un document à l'autre en utilisant des modèles "multi-hop"7
- et enfin préparer un projet de réponse pour chaque question, avec transparence sur le processus de réflexion et les sources utilisées.
- Conformité ESG : Un cabinet d'avocats fournit à ses clients la liste des exigences de publications extra-financières. Il fournit à Documentalist le profil du client et lui demande de :
- Lire toutes les législations applicables dans une base de données sélectionnée de plus de 500 documents,
- Identifier toutes les règles s'appliquant à ce profil de client (en fonction de la taille, de la localisation, de l'industrie, etc.)
- Prendre des notes dans un document avec des liens vers les paragraphes sources.
- Extraction d'informations : Un cabinet de conseil fiscal avec 20 ans d'expérience possède des millions de fichiers dans un disque partagé, principalement des PDFs ou des scans de lettres échangées avec l'administration contenant des réponses à des questions sensibles et complexes. Toutes ces informations sont très précieuses, mais non recherchables. Avec Documentalist, ce client peut demander :
- Avons-nous déjà traité cette question (ou similaire). Comment avons-nous répondu ?
- Qualité des appels : Une compagnie d'assurance souhaite évaluer les appels des clients par rapport à leurs directives de conformité et de qualité, afin d'identifier automatiquement quels appels pourraient nécessiter une double vérification. Ils peuvent demander à Documentalist de :
- lire la transcription des appels
- appliquer un système de notation personnalisé8
- créer un tableau récapitulatif listant tous les appels et leurs scores.
- &hellip : et bien d'autres possibilités.
Si vous avez lu jusqu'ici et que vous êtes intéressé, discutons de votre cas d'usage ! Nous recherchons des partenaires de design pour travailler sur des cas d'usage à forte valeur ajoutée.
Discutons-en !Footnotes
- PageRank est un algorithme d'analyse de liens développé par les fondateurs de Google, Larry Page et Sergey Brin, qui aide à classer les pages web dans leurs résultats de recherche. ↩
- Les modèles de langage de grande taille peuvent être très sensibles à la mise en forme des inputs, comme montré dans Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting. ↩
- Initialement développé par OpenAI, CLIP apprend des concepts visuels à partir de descriptions en langage naturel, comblant efficacement le fossé entre texte et images grâce à un espace de représentation unifié. Il est conçu pour comprendre et générer une large gamme de tâches visuelles sans avoir besoin de données d'entraînement spécifiques à la tâche, ce qui le rend très polyvalent et puissant pour diverses applications. ↩
- Comparer chaque document avec tous les autres implique une complexité temporelle de , qui sera abordée dans un article à venir . ↩
- A donné naissance à la famille des modèles Phi avec Textbooks Are All You Need, Bubeck et al. 2023. ↩
- Inspiré par Scratchpad for Intermediate Computation, Nye et al., 2021. ↩
- Inspiré par Robust Multi-hop Reasoning, Khattab, 2021. ↩
- Inspiré par l'idée derrière LLM-as-a-Judge, L Zheng, 2023. ↩