Présentation de Documentalist



Imaginez quelqu'un dans votre équipe qui aurait mémorisé le contenu de tous les fichiers de votre entreprise et pourrait retrouver n'importe quelle information, quelle qu'en soit la langue. Quelqu'un qui pourrait vous assister pour des tâches impliquant de manipuler de grandes quantités d'informations non structurées (texte, audio, images, ...), et qui n'aurait pas de limite de charge de travail.
Nous vous présentons Documentalist, qui utilise les dernières avancées en matière d'IA pour vous fournir:
Knowledge Base : un index de vos fichiers enrichi par l'IA, pour en constituer la mémoire.
Knowledge Search : un moteur de recherche de nouvelle génération, pour explorer cette mémoire.
Knowledge Work : une plateforme pour automatiser des tâches de traitement d'information.
Confidentialité : l'index de chaqun de nos clients repose dans une enclave cloud privée, qui peut aussi être déployée on-prem.
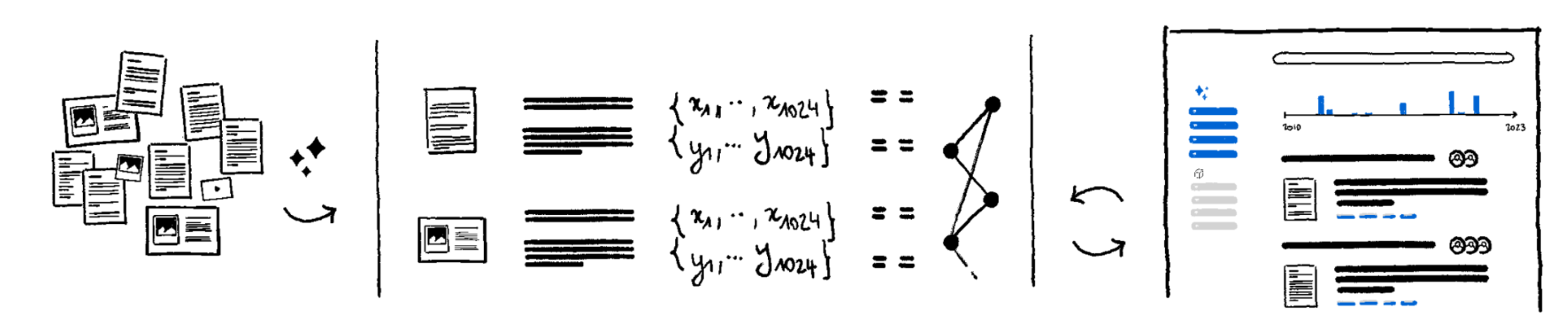
Activer la mémoire de l'entreprise
Les entreprises n'ont pas de mémoire
Dans la plupart des entreprises, les connaissances produites par les employés sont immédiatement perdues. Les Drive et autres Sharepoints sont comme des bibliothèques géantes remplies de livres que personne ne relira jamais, malgré leur valeur… C'est comme si la bibliothèque d'Alexandrie brûlait tous les jours.
Et le Knowledge Management coûte des milliards, en heures passées à rechercher des informations (jusqu'à 2 heures par jour dans le secteur tertiaire). Les solutions de Knowledge Management actuelles échouent souvent par manque de persévérance, ou réussissent mais à grands frais (le BCG compte plus de 1 000 personnes dans son équipe Knowledge, par exemple).
Perdre du temps à chercher des informations et à réinventer la roue n'est pas la seule conséquence. L'entreprise qui ne parvient pas à rendre son Knowledge accessible rate aussi des occasions d'améliorer la qualité de ses services et de ses produits.
L'IA change les règles
Grâce aux dernières avancées en matière de traitement du langage naturel et d'IA générative, il est clair que nous pouvons réinventer la façon d'organiser, extraire et la traiter des informations. Techniquement, mais aussi économiquement.
Les modèles d'IA peuvent comprendre les concepts contenus dans les textes, les images, les vidéos et les fichiers audio, dans la plupart des langues. Nous pouvons les utiliser pour rendre le Knowledge Management moins onéreux (en supprimant la plupart des besoins de classification manuelle, d'étiquetage, etc.) et pour automatiser des tâches de traitement de plus en plus sophistiquées).
Il faut cinq minutes pour créer un "GPT" ou un assistant de ce type à partir de quelques documents, car on n'a pas à se préoccuper du système de recherche. Pour les grands répertoires d'entreprise, c'est une autre histoire. Le seul moyen d'accéder aux documents à grande échelle est de maintenir un index.
Nous commençons donc par là.
Knowledge Base
Documentalist se synchronise avec vos fichiers (fichiers texte (PDF, Word, Docs, Slides...) images, audio, vidéo). Ensuite, il les traite et les indexe sur différents types de bases de données, en utilisant des modèles d'IA pour capturer leur contenu, ainsi que les relations entre les sujets et entités.
Sous le capot :
Dense Embedding: Modèle qui capture le sens d'un texte ou d'une image sous la forme d'un vecteur, utilisé pour la recherche sémantique.Sparse Embedding: Modèle qui combine la correspondance par mots-clés avec des capacités sémantiques. Inventé à La Sorbonne1.Embedding Indexing: mise en oeuvre d'une indexation efficace pour traiter les représentations vectorielles (denses ou éparses) et les rendre requêtables en quelques millisecondes.Named Entity Recognition: Modèle qui labellise automatiquement les organisations, personnes et lieux ("entités").Métadonnées: Les métadonnées associées au fichier (nom, date, collaborateurs, ...), et les métadonnées tierces (associées au fichier mais stockées dans des systèmes tiers (par exemple Salesforce)).Knowledge Graph: afin de découvrir les relations entre les "entités" d'un fichier à l'autre, en utilisant un LLM pour automatiser la génération de graphes2.- Consultez notre blog (ou contactez-nous) pour plus de détails.
Avec cette indexation, Documentalist classe vos documents, et rend leur contenu accessible avec précision. Il les transforme pour ainsi dire en mémoire.
Knowledge Search
Venant tous deux de Google, nous avons été profondément influencés par sa mission de rendre l'information accessible et utile. Comment se fait-il que nous ayons un outil aussi formidable pour effectuer des recherches sur le web, mais que les moteurs de recherche des entreprises soient aussi peu performants?
Nous pouvons faire évoluer les standards grâce aux fonctionnalités suivantes, le développement de certaines étant désormais facilité par l'IA générative.
Keyword Searchbien sûr : localiser rapidement des informations spécifiques,Dense-vector Search: correspondance sémantique entre les requêtes et les passages pertinents,Sparse-vector Search: correspondance entre les mots-clés individuels et les passages sémantiques pertinents,Graph Search: amélioration de la pertinence de la recherche en grâce aux relations entre les entités (personnes, lieux, éléments, concepts) mentionnées dans les fichiers. Exemple : trouver la personne experte d'un sujet donné au sein de l'entreprise.Re-ranking models: cross-encoders propriétaires formés sur des datasets spécifiques au domaine de chacun de nos clients.Query-intent models: joindre l'intention de la requête à la méthode de recherche pertinente (mot-clé, dense, sparse ou graph).
v0.1 de notre moteur de recherche chez un de nos design partners. La fonctionnalité de Graph Search n'est pas encore intégrée.Knowledge Work
Nous pouvons désormais retrouver les informations que vous cherchez. Vous aurez peut-être envie d'aller plus loin et d'effectuer des opérations de traitement de ces informations.
Les cas d'utilisation que l'IA générative permet d'envisager sont innombrables. En voici quelques-uns :
- Supposons que vous travailliez sur un appel d'offres : vous pouvez demander à Documentalist d'en lire les questions, de scanner tous les documents correspondants pour chacune d'entre elles, de prendre en notes les passages pertinents dans un bloc-notes3, de passer d'un document à l'autre en utilisant des modèles de raisonnement (multi-hop reasoning4), pour rédiger enfin une ébauche de réponse, tout en gardant une trace du processus de réflexion et en citant les sources utilisées.
- Ou bien vous vous occupez du service client: vous demandez à Documentalist de lire des transcriptions d'appels clients, de leur appliquer un scoring5, pour les trier et en extraire les sujets les plus importants.
- Ou alors tout simplement, vous identifiez des slides que vous pourriez réutiliser pour votre prochain meeting, à l'aide d'un modèle Vision-Instruction comme "LLaVA", spécialisé sur les données de votre entreprise.
- Ou encore, vous pourriez demander à Documentalist d'identifier quels sont les contrats dont des clauses sont en opposition à telle ou telle nouvelle réglementation, en utilisant des modèles de raisonnement qui compare les documents (ce qui conduit à O(N²) appels aux modèles).
- Ou... beaucoup d'autres cas d'utilisation avec lesquels nos premiers clients font preuve de créativité. Quel sont les vôtres ?
Il ne fait aucun doute qu'il sera bientôt possible de déléguer des tâches aussi complexes à des machines. Chaque employé ou équipe pourra programmer ces tâches à l'aide d'instructions en langage naturel. Ce sera un peu comme utiliser Excel aujourd'hui, et réduira le besoin de logiciels ad hoc.
Il n'y aura pas de modèle unique, mais de multiples modèles spécialisés par tâche, qui devront être orchestrés par l'entreprise.
- Confidentialité en particulier pour les entreprises européennes.
- Transparence : les poids des modèles doivent être accessibles.
- Puissance de calcul : les coûts d'inférence devront être maîtrisés.
Confidentialité
Attendez. Indexer les informations de l'entreprise!? Où?
Les solutions SaaS s'appuient généralement sur une infrastructure multi-tenant pour fournir leurs services à moindre coût, mais cela a ses limites en matière de confidentialité.
Nous assurons une meilleure confidentialité, tout en continuant à mutualiser les parties stateless de notre solution. En d'autres termes, chaque client dispose de son propre conteneur de base de données, de ses propres disques, de son propre conteneur d'API, etc. Tous ces conteneurs fonctionnent à l'intérieur d'une enclave dédiée, avec des règles de réseau strictes permettant uniquement à vos conteneurs de communiquer entre eux.
- Notre solution repose sur des projets certifiés CNCF, parmi lesquels : Kubernetes, Helm, Cilium, Envoy, Rook et Prometheus.
- Nous proposons un vGPU géré avec le même niveau de confidentialité que notre enclave, en exploitant la fonctionnalité Nvidia MIG 6.
- Le fournisseur Cloud pour notre offre managed est Scaleway FR, nous utilisons des serveurs dans le datacenter de Paris.
- Mais vous pouvez exécuter votre enclave où vous le souhaitez : optez pour notre cluster Kubernetes géré à moindre coût, ou choisissez un déploiement on-prem.
Modèles Open-Source = Transparence + Performance - Coûts
Transparence + Performance : Les modèles ouverts (≥ open-weights) permettent aux utilisateurs de les évaluer, ce qui est essentiel pour la transparence. Leurs performances rattrapent celles des modèles fermés les plus célèbres (par exemple, GPT-4, Claude, Gemini). Ils peuvent désormais être considérés comme des modèles fondamentaux robustes, prêts à être spécialisés (affinés) pour des applications personnalisées.
Coûts : La quantité de calcul nécessaire pour une tâche donnée diminue à une vitesse stupéfiante. L'exécution de modèles open-source sur nos propres serveurs permet de décider du compromis entre qualité, rapidité et coût. Choisir le bon modèle pour une tâche donnée permet d'optimiser les coûts: pour de nombreuses tâches, utiliser de très grands modèles n'a aucun sens (ni du point de vue économique, ni du point de vue écologique).
Le "coût de l'intelligence" diminue plus rapidement que la célèbre loi de Moore, ce qui laisse supposer que de plus en plus de cas d'utilisation pourront être explorés dans les années à venir, en tirant parti des technologies open source pour une transparence et un contrôle des coûts complets.
Devenez notre design partner !
Si vous avez lu jusqu'ici, vous êtes peut-être intéressé par une collaboration avec nous !
Nous recherchons des entreprises pour engager un programme de R&D : nous construisons votre Knowledge Base, nous vous fournissons notre moteur de Knowledge Search, et nous concevons ensemble un cas d'utilisation Knowledge Work, que nous intégrons ensuite à notre produit et maintiendrons au fil du temps.
Nous sommes principalement intéressés par des design partners issus d'industries où les employés manipulent de grandes quantités d'informations non structurées (conseil, juridique, création, finance, assurance, ...). Mais notre moteur de recherche peut être utile à toute entreprise qui a des enjeux de Knowledge Management.
Contactez-nous !Footnotes
- Les embeddings Sparse ont fait l'objet d'une certaine attention avec SPLADE by Formal, 2021 à La Sorbonne. Nous sommes contributeurs à l'extension opensource
pg_sparsepour PostgreSQL. ↩ - Nous nous inspirons des avancées dans la génération de knowledge graphs en utilisant des LLM : Exploring Large Language Models for Knowledge Graph Completion par L. Yao, 2023. ↩
- L'utilisation d'un scratchpad peut être considérée comme une sorte de calcul adaptatif, l'étude qui nous inspire le plus a été publiée par les chercheurs de Google : Scratchpad for Intermediate Computation par Nye et al, 2021. ↩
- Les questions complexes nécessitent de multiples informations provenant de plusieurs documents dans un champ de recherche très vaste. Cela a été étudié sous la terminologie multi-hop, et l'article qui nous inspire le plus a été publié par des chercheurs de Stanford avec Robust Multi-Hop Reasoning at Scale via Condensed Retrieval par Khattab, 2021. ↩
- Notre idée est d'exploiter des LLM puissants comme un moyen d'approximer les préférences humaines dans des scénarios complexes de notation/évaluation, comme cela a été étudié dans LLM-as-a-Judge par L Zheng, 2023. La semaine dernière, les chercheurs de Meta ont réutilisé cette technique dans Self-Rewarding Language Models par W Yuan, 2024, montrant que la puissance de LLM-as-a-Judge est plus élevée que la puissance de production de nouvelles sorties, conduisant à un cercle vertueux où le modèle peut s'améliorer de manière significative. ↩
- MIG signifie Multi-Instance GPU et nous permet de dédier une tranche d'un H100 à votre enclave en isolant le calcul, pour une parfaite confidentialité. ↩