L’opportunité des données déstructurées


Grâce aux récentes avancées en matière d'intelligence artificielle, l'automatisation du traitement des données déstructurées représente une opportunité immense pour les entreprises. Pour les sociétés de services professionnels en particulier – la finance, le droit, la banque, l'assurance, et autres – il n'est pas seulement question d'avantage concurrentiel, mais de survie. L'opportunité est d'offrir de meilleurs services en transformant la structure de coûts, mais la réalisation de cette opportunité n'est pas triviale. La raison d'être d'Entropia est d'accompagner cette transition.
80 % des données d'entreprise sont déstructurées, laissant de nombreux workflows non automatisés
Les données déstructurées désignent les informations qui ne s’intègrent pas dans des modèles de données traditionnels comme des tableurs ou des bases de données. Il s’agit, par exemple, des e-mails, des contrats juridiques, des fichiers PDF, des présentations, des mémos, des chats, du service client, des comptes rendus de réunions, des posts sur les réseaux sociaux, etc. Contrairement aux données structurées, qui sont facilement organisables et constultables, les données déstructurées n'ont pas de format préétabli, ce qui rend leur analyse et leur intégration dans des processus automatisés plus complexes.
Bien que 80 % des données d'entreprise soient déstructurées, la plupart des automatisations ont jusqu'à présent porté sur les données structurées, laissant une grande partie de de l'information sous-exploitée. Jusqu'à présent.
Automatiser les workflows de données déstructurées est difficile
L’automatisation de processus de données déstructurées se heurte à trois obstacles principaux :
- Pré-traitement : Avant de pouvoir analyser les données déstructurées avec des modèles d'IA, les données doivent être standardisées et converties en un format que les modèles peuvent appréhender. Ce processus est à la fois chronophage et coûteux en ressources, en raison de la variété des formats de documents nécessitant chacun des techniques spécifiques à orchestrer, et de l'énorme volume de données à traiter simultanément. Un défaut de pré-traitement mène à des résultats incohérents, rendant l'effort d'automatisation moins fiable, voire carrément inutile. "Garbage-in, garbage-out"
- Modèles fondationnels accessibles : Les modèles d'IA actuels peuvent analyser des données déstructurées, mais l'équilible entre précision et coût n'est pas simple à trouver. Les plus gros modèles peuvent s'avérer très coûteux, tandis que les alternatives moins chères peuvent ne pas offrir la précision requise.
- Contrôle utilisateur : Les entreprises qui se lancent dans l'automatisation de processus d'analyse de données par IA doivent pouvoir injecter leur propre logique métier, et surtout garder le contrôle sur les opérations prises en charge par des modèles.
Les avancées en traitement du langage naturel réduisent ces barrières
Les défis sont de taille, mais l'IA évolue rapidement, et deux grandes tendances en traitement du langage naturel (NLP) font tomber des barrières à l'automatisation des workflows de données déstructurées:
- La valeur par token augmente : Grâce aux améliorations des architectures de modèles et de la qualité des données d'entraînement, chaque unité d'information analyse ou produite par un modèle — chaque « token » — fournit des résultats de meilleure qualité.
- Le prix par token diminue : Les avancées dans le hardware et la disponibimlité accrue de modèles d'IA flexibles font baisser les coûts d'inférence.
Ces dynamiques augmentent considérablement la valeur des investissements dans le pré-traitement des données déstructurées, car les applications en aval deviennent de plus en plus puissantes et génératrices de valeur.
Les modèles open-source sont prêts à être utilisés en entreprise
Les modèles de langage open-source (LLM) ont comblé l’écart avec les modèles propriétaires, grâce aux avancées du mouvement open-source1. Autrefois considérés comme inférieurs en termes de performance, les modèles open-source rivalisent désormais au plus haut niveau, offrant précision, rapidité et polyvalence.
Pour les entreprises, ce changement présente des avantages considérables. Les modèles open-source peuvent considérablement améliorer la qualité des services tout en réduisant les coûts. Ils peuvent être personnalisés et ajustés pour répondre aux besoins et aux données spécifiques des entreprises, offrant ainsi une pertinence accrue. Leur taille peut être optimisée pour une tâche donnée, réduisant ainsi les coûts d'infrastructure nécessaires pour l'inférence. Les entreprises peuvent les intégrer à leurs systèmes existants sans les restrictions souvent imposées par les solutions propriétaires, et sans être tenues par des politiques de prix à l'utilisateur, typiques des solutions propriétaires. De plus, la transparence des LLM open-source permet de maîtriser le comportement des modèles, renforçant la sécurité. Les entreprises peuvent auditer, comprendre et piloter précisément comment le modèle fonctionne.
L'opportunité d'automatiser les traitements de données déstructurées est immense, en particulier pour les sociétés de services professionnels
Toutes les entreprises peuvent, et vont, bénéficier de ces nouvelles technologies, mais l'opportunité est particulièrement transformative pour les services professionnels. Du droit à la finance, en passant par l'assurance, le conseil ou l'audit, l'automatisation des traitements de données déstructurées sera le grand sujet de la prochaine décennie.
Polices d'assurance, contrats, études de marché, jurisprudences, justificatifs en tous genre, … Les services professionnels reposent sur une documentation complexe. Désormais, une grande partie de cette documentation peut être analysée, voire produite par des machines. De la même manière que les entreprises délèguent depuis longtemps certains calculs à leurs ordinateurs via Excel, ces professions auront bientôt des machines capables de prendre en charge le traitement de documents complexes, ce qui transformera à la fois leurs capacités et leurs structures de coûts.
Dans le domaine juridique, analyser de vastes quantités de jurisprudences, de textes de loi, de documents, d’e-mails ou de précédents juridiques (recherche documentaire, e-discovery) prendra quelques secondes au lieu de plusieurs heures. En finance, l’analyse automatique des états financiers, audits ou rapports libérera des heures de travail manuel, accélérant les prises de décisions. Le secteur de l'assurance connaîtra des transformations radicales dans le traitement des réclamations ou la détection des fraudes, etc. La liste s'allonge chaque jour.
Alors que les précédentes vagues d'innovations technologiques ont plutôt concerné l'automatisation de tâches de traitement de données structurées, la prochaine vague portera sur les données déstructurées. D'ici cinq ans, le paysage des services professionnels sera radicalement différent, l'IA jouant un rôle central dans la manière dont les données déstructurées seront analysées, interprétées et utilisées. L'IA permettra aux professionnels de se concentrer sur des tâches à plus forte valeur ajoutée, tout en améliorant la précision et la rapidité de leurs services. Cette évolution est sur le point de remodeler le paysage concurrentiel dans ces secteurs.
Entropia libère le potentiel de vos données déstructurées
Entropia est au cœur de cette transformation. Nous proposons une gamme d'outils et de services afin de rationaliser le traitement des données déstructurées. Voici un aperçu :
- Qualité des données : pré-traitement des documents
Nous transformons des fichiers déstructurées et désordonnées en un format que des modèles d'IA peuvent facilement digérer, et nous sommes capables de le faire à grande échelle. Cela garantit que les modèles aval travaillent sur des données de qualité, améliorant non seulement la fiabilité des informations produites, mais réduisant également leur coût habituel.
- Recherche et analyse de documents
Notre Documentalist peut organiser et classer une base de connaissances, récupérer n'importe quelle information parmi des millions de fichiers, quelle que soit la langue, et analyser des documents à la volée.
Par exemple, un de nos clients (un cabinet de conseil fiscal) utilise Documentalist pour trouver des réponses à des questions dans ses dossiers passés. Lorsqu'une question est soumise, Documentalist consulte les archives du cabinet, trouve tous les documents traitant de sujets similaires, les lit, et répond à la question tout en référençant ses sources. Avant Documentalist, ces connaissances étaient enfouies dans le système de fichier du cabinet sous forme de PDF et de scans, et les employés n'avaient aucun moyen d'exploiter cet historique. Grâce à Documentalist, ils produisent des résultats meilleurs et plus rapides.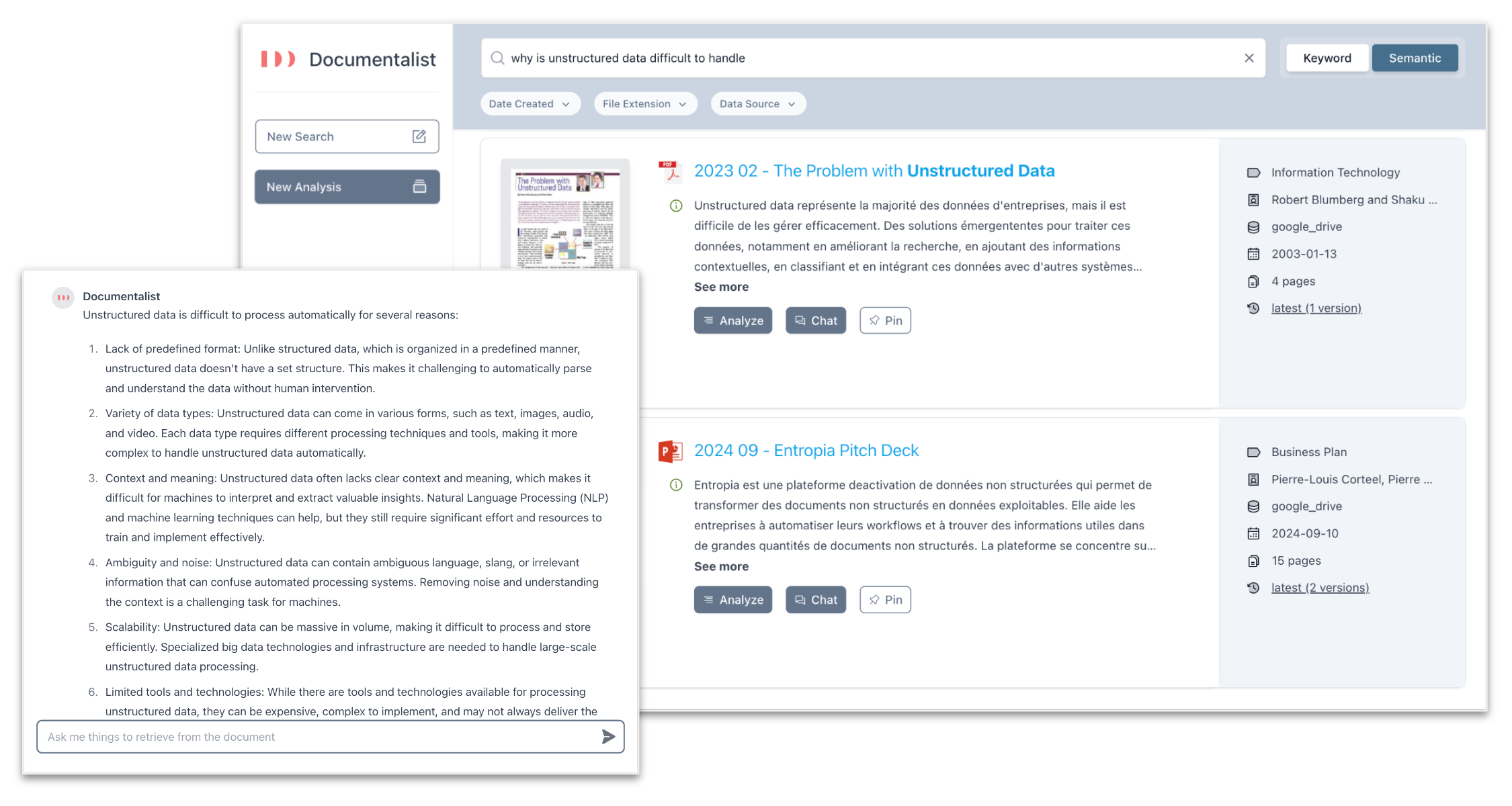
- Structurer les données déstructurées
Une autre capacité très puissante d’Entropia est de permettre aux utilisateurs de générer des insights structurés à partir de fichiers non structurés. Parce que nous sommes capables d'analyser le contenu des fichiers à la volée, nous pouvons effectuer de multiples analyses sur de multiples documents, simultanément.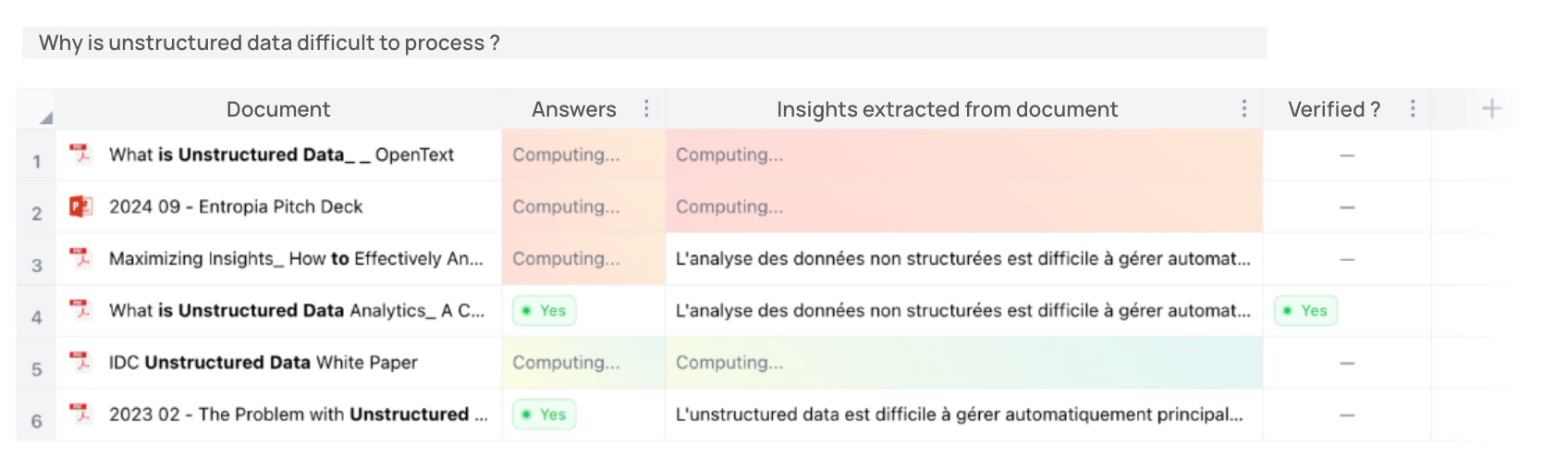
Par exemple, nous collaborons avec des chirurgiens sur un projet de recherche médicale. Ils voulaient extraire des statistiques à partir de leurs dossiers patients, mais les données étaient piégées dans des PDF et des textes non structurés, rendant les opérations de recherches impossibles. Nous avons converti les PDF en un format texte structuré, puis généré automatiquement une base de données à partir du texte des dossiers patients – éliminant ainsi le besoin de saisie manuelle et accélérant la recherche médicale. - Automatiser les process
Chaque entreprise a des processus, des taxonomies et des structures de données uniques qui la distinguent. Les solutions standardisées échouent souvent à relever les défis spécifiques et les nuances de ces processus. C’est pourquoi nous allons plus loin en aidant les entreprises à automatiser des tâches répétitives spécifiques, améliorant ainsi l'efficacité et réduisant les erreurs.
Nos technologies sont polyvalentes et adaptables, nous permettant de répondre aux besoins de divers secteurs et métiers. Nous nous intégrons facilement aux systèmes existants. Nous développons même des produits sans interface utilisateur (no-UI) qui simplifient le test, le déploiement et la mise en production, permettant une adoption rapide et des gains de productivité immédiats.
Footnotes
- Cet été, Meta a publié Llama 3.1, dont les performances sur la plupart des benchmarks établis ont renforcé la tendance : les modèles propriétaires n'ont qu'une légère avance sur leurs homologues open-source, et cet écart prend généralement quelques mois à être comblé – comme l'illustre le graphique suivant :
 ↩
↩